关于robots.txt的使用
最近跟朋友在讨论robots.txt 的使用问题,有几个朋友给我发了下他们在使用robots.txt过程中出现的问题。发现这些朋友的robots.txt里面居然有个相似的共同点如图:
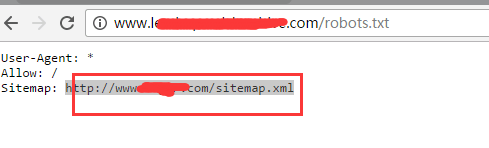
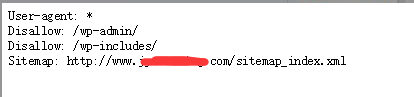

没错,他们都把网站地图sitemap放到了robots.txt文件里面!如果他们使用了网站站长工具,无一例外会在sitemap提交栏里收到一条警告提示, URL blocked by robots.txt,sitemap被robots.txt屏蔽了!看完我只想对他们说四个字:no zuo no die! 把sitemap放进robots里面,不是作死是什么。他们都很疑惑,为什么会这样,网上很多大神的教程里不是说了,在robots.txt里面放入sitemap有助于google抓取和收录嘛?事实真的是这样的嘛?刚好相反,放了sitemap到robots文件里面的网站,收录都差!首先,我们来看看,google官方对robots.txt文件的定义:
robots.txt 文件位于您网站的根目录下,用于表明您不希望搜索引擎抓取工具访问您网站上的哪些内容。
一般会用到 disallow指令,表明不希望被搜索引擎索引的资源及文件。看到这里,相信有朋友会说了,哎哟,那我用allow不是表示我允许访问了嘛?事实真的如此吗?我们再看看官方介绍的另外一句话:
最简单的robots.txt文件会用到两个关键字:User-agent和Disallow。User-agent(用户代理)是指搜索引擎漫游器(即网页抓取工具软件);Web Robots Database 中列出了大多数用户代理。Disallow 是针对用户代理的命令,指示它不要访问某个特定网址。反之,如果要允许 Google 访问某个特定网址,而该网址是已禁止访问的父级目录中的子目录,则可以使用第三个关键字 Allow。
使用上述关键字时应遵循以下语法:
User-agent: [the name of the robot the following rule applies to]
Disallow: [the URL path you want to block]
Allow: [the URL path in of a subdirectory, within a blocked parent directory, that you want to unblock] 参考官方解析
再来看看google官方那边给出的常见的robots.txt的写法

大家有没有发现一些规则?google这边对于allow这类文件的规则写法。基本都是特指的一些网页或特定蜘蛛类型才会去使用。网页中正常的sitemap网址就真的不需要添加到里面去了。没有任何一种证据可以证明robots txt加了sitemap之后你们网站收录就增加或加速了几倍吧?
好了,看到这里大家都清楚了,allow命令是在允许google访问某个特定网址,而该网址是已被禁止访问的父级目录中的子目录,或者指定蜘蛛类型才使用的。况且,上面两个朋友发给我的robots文件的写法,都是错误的!除了sitemap的问题,其他指令也有误。建议不懂的朋友还是不要乱用吧!

